date: 2016-01-10 23:10:20
tags:
1. 参考文献
编程珠玑 - 算法优化 - 过滤敏感词
NFA/DFA算法
Java实现敏感词过滤
DFA敏感词过滤——java版
2.简介
DFA即Deterministic Finite Automaton,也就是确定有穷自动机,它是通过event和当前的state得到下一个state,即event+state=nextstate。
闲话不多说,直接上图: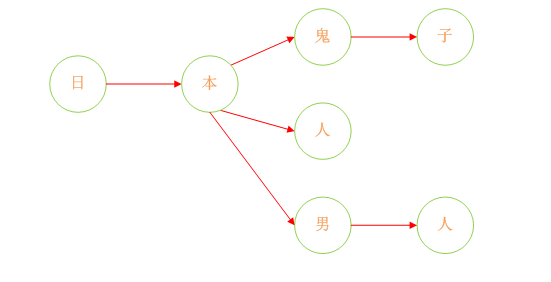
将此图翻译成代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27中 = {
isEnd = 0
国 = {<br>
isEnd = 1
人 = {isEnd = 0
民 = {isEnd = 1}
}
男 = {
isEnd = 0
人 = {
isEnd = 1
}
}
}
}
五 = {
isEnd = 0
星 = {
isEnd = 0
红 = {
isEnd = 0
旗 = {
isEnd = 1
}
}
}
}
算法的关键就是组装成一个带有状态的tree。
第一步,在hashmap中查询“中”,如果不存在,则直接构建此树。
第二步,如果在hashmap中查询到了“中”,则设置hashmap=hashmap.get(“中”),然后跳转至第一步,匹配“国”。
第三步,判断该字是否是最后一个,是,isEnd=1, 否,idEnd=0。
接下来过滤文本内容。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16for(int i = beginIndex; i < txt.length() ; i++){
word = txt.charAt(i);
nowMap = (Map) nowMap.get(word); //获取指定key
if(nowMap != null){ //存在,则判断是否为最后一个
matchFlag++; //找到相应key,匹配标识+1
if("1".equals(nowMap.get("isEnd"))){ //如果为最后一个匹配规则,结束循环,返回匹配标识数
flag = true; //结束标志位为true
if(SensitivewordFilter.minMatchTYpe == matchType){ //最小规则,直接返回,最大规则还需继续查找
break;
}
}
}
else{ //不存在,直接返回
break;
}
}
对特殊字符过滤
有时候敏感词会出现一些变体,如强,,,奸 强 奸 强*,,,奸。
这个时候就需要对文本做一些预处理。方法如下:1
2
3String regexp = "[^a-zA-Z0-9\u4E00-\u9FA5]";
String content = "强,,,奸 强 奸 强*,,,奸";
String str = content.replaceAll(regexp, "");
效果杠杠的
#####3.测试数据
如图所示,敏感词库共有1071课树,匹配的文本共1636字,包含94个铭感词,完全匹配出来只需3毫秒。

如果在相同测试条件下,只需判断文本中是否存在铭感词,则效率更快,只需0毫秒。